Идея происхождения арабских цифр у новых хронологов
Обсуждение. Изложена, на наш взгляд, крайне интересная гипотеза о происхождении «индо-арабских» цифр от русской цифири (цифровых значений букв азбуки). Приведены обоснования, которые позволяют сделать вывод о том, что В ПЕРВОМ ПРИБЛИЖЕНИИ ДАННАЯ ГИПОТЕЗА ИМЕЕТ ПРАВО НА СУЩЕСТВОВАНИЕ. Действительно, многие «арабские» или «индо-арабские» цифры похожи на буквы русского алфавита.
Однако, некоторые детали данного научного предположения, тем не менее, вызывают сомнение. Так, если полагать, что цифры используются для 1) пересчета (перечисления), 2) подсчета (простейших арифметических действий), 3) решения уравнений, то приведенные авторами доказательства отсутствия нуля третьим уровнем развития математики не убеждают. Ноль бывает нужен уже на втором уровне, когда вычитание числа самого из себя приводит к цифре НОЛЬ. Так что востребованность цифры НОЛЬ возникает гораздо раньше XVI века, а именно тогда, когда математики осваивают ВЫЧИТАНИЕ, а вовсе не тогда, когда они РЕШАЮТ УРАВНЕНИЯ.
Далее, совершенно не объяснена ПУТАНИЦА 5 и 6 и 3 и 7. В гипотезе она отмечена, но «повисает в воздухе», иными словами, ГИПОТЕЗА НЕ ЗАВЕРШЕНА.
Наконец, ряд трансформаций чисел слишком сложен. Допустимо зеркальное отражение (в древних текстах зеркальное начертание букв - не редкость); намного реже встречается перевернутое начертание букв. Однако сочетание переворачивания буквы и зеркального отражения мне за всю мою эпиграфическую практику НЕ ВСТРЕТИЛОСЬ НИ РАЗУ, так что здесь гипотеза новых хронологов ЭПИГРАФИЧЕСКИ НЕ ОБОСНОВАНА.
Полагаю, что все эти недочёты гипотезы обусловлены тем, что хронологи хотят обосновать наиболее недавнее появление «индо-арабских» цифр, не ранее XVI века, что удивительно. Известно, что математические операции типа вычитания и деления математики делали еще в античности. А для этого, как мы знаем, существовали египетская, греческая и римская цифровые системы. И не исключено, что параллельно с этими цифрами существовали и русские цифры. Однако для утверждения этого необходимо выдвинуть собственную гипотезу, которая, учитывая все достижения новых хронологов, дала бы более точное предположение о более раннем возникновении «индо-арабских» цифр.
Наша гипотеза. Мы исходим из того, что «индо-арабские» цифры существовали много тысяч лет назад. На геоглифе Лемурии нами (Л.С. Шершневым и мной) была обнаружена цифра 6435; существуют и другие древние цифры. Именно поэтому гипотеза новых хронографов кажется нам слишком короткой по хронологии.
С другой стороны, сами алфавиты - весьма недавние изобретения человечества, намного уступающие по времени той письменности, которую они отображают. Поэтому ориентироваться на греко-славянский алфавит с его цифирью нет никакого смысла. Напротив, на наш взгляд, сама цифирь может помочь в решении проблемы алфавита.
А именно: если присмотреться, то 9 - буква Я, 8 - буква Ю, 7 - скорее буква А, чем Т, наконец, 1 - буква I, а 0 - буква О. Иными словами, мы имеем РЯД ГЛАСНЫХ. Полагаю, что и остальные буквы, вошедшие в «индо-арабские» цифры - тоже буквы для обозначения гласных звуков. А именно: 6 - буква Ь, 2 - буква Ъ (повёрнутая на 180 градусов), 4 - буква У и 5 - буква И. Замечу, что цифра 1 - не столько буква I латинского (и греческого) алфавита, сколько общий символ для обозначения гласного звука в рунице, тогда как остальные буквы принадлежат протокириллице (рунам Рода). Таким образом, ряд от 1 до 0 есть ряд гласных: I (гласная вообще), Ъ, Е (зеркально отраженная как З), У (рис. 4), И, Ь, А, Ю, Я, О. Здесь отсутствуют только гласные Ы, Э и Ё; первая является вариантом гласной И, вторая появляется довольно поздно (у этрусков) как вариант буквы Е, третья была предложена Карамзиным в XVIII веке.

Рис. 4. Четверка на дате из гравюры А. Дюрера [1:171, рис. 71]
Если наша гипотеза верна, она показывает, что в древности порядок букв в азбуке был иным, и начинался он с общего обозначения гласных звуков в рунице (рунах Макоши). Только затем шли руны Рода. Если убрать НОЛЬ, который появился позже, и ЕДИНИЦУ, которая заимствована из другого алфавита, остается 8 цифр (2-9), или, говоря по-германски, один АТТ (Acht), одна восьмёрка - единица измерения числа букв в германских футарках. А внутри также имеется порядок, где соответствие наблюдается через половинку атта, то есть, через 4 цифры. В самом деле: число 2 - это Ъ, число 6 - Ь; число 4 - У, число 8 - Ю. В других случаях соответствие менее заметно: число 3 - Э (одно из написаний Е), число 7 - А (одно из написаний - наклонное, с плохо выраженной перекладиной, которая не доходит до противоположной опоры); число 5 - И, число 9 - Я (обе буквы для йотированных гласных). Иными словами, чётные цифры имеют больше сходства в характере букв, чем нечетные.
Обращает на себя внимание тот факт, что уже в то древнее время, когда буквы получили цифровое значение, так называемые «редуцированные» гласные (чья редукция произошла гораздо позже, почти в наши дни) считались вполне полноценными звуками, которые нашли отражение в виде цифр. Это очень важно для понимания возникновения и развития фонетики РЯ. Возможно, что первыми собственно гласными звуками как раз и явились редуцированные; они и были зафиксированы на письме в первую очередь. Позже появились гласные полного образования, а еще позже - йотированные гласные. Иными словами, цифирь отражает как раз порядок создания гласных букв в буквенной письменности.
Данная гипотеза коррелирует с современными разделами лингвистики РЯ, изучающими фонетику. Многие авторы учебников предпочитают начинать именно с описания вокализма, позже переходя к описанию консонантизма. Почему именно в таком порядке? Потому, что согласных, полугласных и сонорных звуков гораздо больше, чем гласных, и если бы возникла потребность на их основе создавать цифры, то не для десятичной системы счисления, а для систем с гораздо большими основаниями (двадцатиричной, двухдюжинной и т.д.).
Если продолжить логику построения первичной системы организации букв (протоалфавита), то вслед за гласными буквами должны идти полугласные, а затем сонорные, которые в ряде славянских языков могут играть роль гласных. Полугласным является ЙОТ, который в качестве буквы изображается как Й. Правда, в белорусском языке существует также полугласный У, однако он возникает на месте исторического звука Л в глаголах, то есть, этот звук (и соответствующая ему буква) не первичен. Что касается сонорных, то это - Л, М, Н, Р. Если теперь соединить указанные буквы, мы получаем ряд Й, Л, М, Н, Р. В современном алфавите мы видим несколько иную последовательность букв: И, Й, К, Л, М, Н, О, П, Р. Иными словами, ЙОТ притянул к себе И, и теперь именно И, а не Й получило цифровое значение 10 (единицы второго разряда), тогда как Й никакого цифрового значения не имеет. Иными словами, Й как бы вообще изъят из цифрового употребления. Затем вклинилась буква К, имеющая цифровое значение 20. далее следуют подряд три сонорных звука со значениями 30, 40 и 50. Но буква Р отнесена на 2 позиции позже и заканчивает этот атт значением 80.
Если продолжить фонетическую логику протоалфавита РЯ, то затем должны располагаться буквы для согласных, которые можно тянуть, типа З-С, Ж-Ш, отчасти В-Ф, фрикативный Г-Х. Предпоследними должны следовать взрывные согласные типа Б-П, Д-Т, тогда как на самом конце должны стоять аффрикаты (как сложные согласные с взрывным элементом) типа ДЗ-Ц, ДЖ-Ч. До некоторой степени эта логика прослеживается и в современном алфавите РЯ, где буквы Ц и Ч являются одними из последних. Таким образом, второй атт мог начинаться с Й и содержать Л, М, Н, Р, Ж, Ш, З, С, то есть, полугласный, сонорные и щелевые.
Третий атт должен начинаться с буквы О, оставшейся незадействованной, и содержать буквы для взрывных согласных (их как раз набирается целый атт): Б, П, Г, К, Д, Т, В, Ф. Наконец, четвертый атт должен включать все оставшиеся неупомянутыми буквы, в том числе непарные; он мог бы начинаться с буквы Ы, и далее включать в себя Х, Ц, Ч, Щ, а также добавленные позже Э и Ё. Таким образом, получается 3 полных атта по 9 букв (всего 27) и один неполный (в 7 букв). Итого - 34 буквы, но одна, самая первая - лишняя, представитель другого алфавита (руницы).
Интересно, что деление на атты сохранилось в германских футарках. При этом младший содержит 2 атта, более древний старший - 3 атта, и самый древний (древнеанглийский) 4 атта. Правда, там атты содержали по 8, а не по 9 букв (рун).
От цифр к цифири. Согласно данной гипотезе праалфавита, первый атт представлял собой цифры от 1 до 9, возникшие из букв для гласных звуков русской речи. Для позиционной системы другие буквы не требовались. Когда потребовался ноль, была задействована еще одна гласная буква, О. Но так было до тех пор, пока на всей земле господствовал русский язык и русская письменность.
Вполне понятно, что позже, по мере возникновения этносов, а затем этнических языков, этнических видов письма и, наконец, после создания этнических алфавитов должны были возникнуть и этнические системы цифр. Здесь могли произойти разного рода трансформации. Например, первый знак в виде вертикальной палочки мог получить иной смысл, скажем, пониматься как А. Например, в арабском языке вертикальная палочка и есть АЛЕФ. Но тогда следовало исключить вторую букву А в виде 7. С другой стороны, буквы Ъ и Ь, которые могли остаться в виде цифр, в языке данного этноса могли не иметь соответствующих звуков, и потому быть исключенными из алфавита. А на их место из других аттов могли быть заимствованы похожие знаки букв. Например, на второе место вместо несуществующего в латинском языке звука, обозначенного буквой Ъ, могла придти похожая буква, например, b. На третье место - нечто похожее на Э, но без перекладинки - С. А затем - похожие на нее буквы D и G, которые оттеснили букву Е. Только Е, которая раньше была третьей, теперь стала пятой, после D, а после нее встала очень похожая на нее буква F, и только затем похожая на С буква G. А замкнули первый атт звуком, близким к G, и обозначаемым буквой Н. Так русский порядок букв был заменен иным. Теперь критериями последовательности букв стали не фонетические принципы, а сходство по начертанию или (в меньшей степени) по звучанию. А алфавит стал носителем цифири.
Но был разрушен и принцип позиционного начертания цифр. Он был заменен полупозиционным принципом привлечения для старших разрядов букв второго и третьего атта. Хотя этнические языки, получившиеся на базе русского, были чуть беднее по фонетике, и уже частично или полностью растеряли четвертый атт, но второй и третий атт у них сохранились, что дало возможность изображать буквами числа до тысячи. А затем с помощью особых значков увеличивать ту же запись в тысячу или миллион раз. Для простой записи цифр и для самых несложных вычислений такой способ представления чисел был хотя и не очень удобен, но вполне терпим. Зато он отличался от русской системы счисления и от русского праалфавита, которые постепенно были забыты.
Обсуждение. Предложенная гипотеза полнее, чем гипотеза Носовского-Фоменко, помогает понять возникновение цифр из начального русского алфавита (праалфавита) и тем самым подтвердить возможность существования древнейшей математики, которую нам подтверждают труды многих исследователей по истории математики. В нашей гипотезе не только сохраняется основная мысль гипотезы Носовского-Фоменко о том, что цифры произошли из русского алфавита, но устраняются некоторые шероховатости, связанные с необъяснимыми и немотивированными заменами 5 и 6, а также 3 и 7.
Наша гипотеза праалфавита позволяет не только понять происхождение «индо-арабских» цифр, но и понять примерную последовательность букв в гипотетическом праалфавите русского языка. А само примерное составление праалфавита окажется полезным при чтении древнейших надписей - не исключено, что на каком-то из храмов он будет воспроизведен, но пока он нами не был предложен, мы его не смогли бы опознать. Теперь мы будем к этому готовы. Кроме того, предполагаемый праалфавит (который, разумеется, нуждается в уточнении ряда деталей) может оказаться полезным при исследовании древнейших алфавитов различных народов древности.
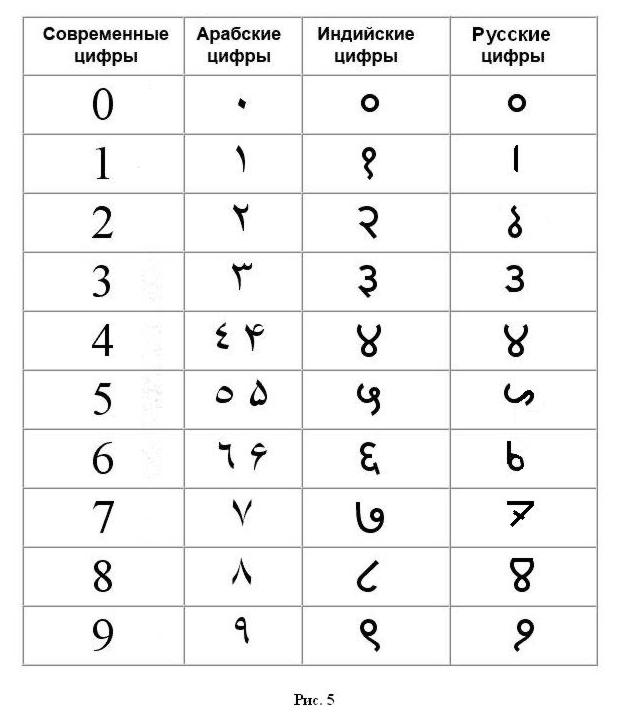
Рис. 5. Предполагаемые русские цифры праалфавита, стилизованные под индийские
Заключение. Если алфавит (хотя бы его начальный атт) и система цифр в какое-то время выглядели совершенно одинаково, то это оказывается еще одной чертой древнейшего синкретизма. До сих пор нам удалось показать синкретизм рисунка и вписанного в него текста. А теперь, похоже, речь идёт о единстве букв и цифр русского праалфавита.
Литература
1. Носовский Г.В., Фоменко А.Т. Великая Смута. Конец Империи. - М.: Астрель: АСТ, 2007, 383 с., ил. Новая хронология для всех.
2. Стройк Д.Я. Краткий очерк истории математики. - М.: Наука, 1969
3. Рыбников К.А. История математики. - М.: МГУ, 1974
4. Энциклопедия элементарной математики. Кн. 1. Арифметика. М.-Л.Государственное издательство технико-теоретической литературы, 1951
5. Словарь русского языка XI-XVII веков. Вып. 1-19. М.: Наука, 1975-1987
6. Черных П.Я. Историко-этимологический словарь современного русского языка. Т. 1, 2. -М.: Русский язык, 1993
7. Гутер Р.С., Полунов Ю.Л. Джироламо Кардано. - М.: Знание, 1980. (Творцы науки и техники)
Написать отзыв
Вы должны быть зарегистрированны ввойти чтобы иметь возможность комментировать.