What is the Difference between the pre(proto)-Slavic and Slavic Tribes?
What is the Difference between the pre(proto)-Slavic and Slavic Tribes?
V.A. Chudinov
Really, what is the difference between Slavic, Pre-Slavic and Proto-Slavic tribes? The brightest feature of every ethnic is its language. The modern comparative linguistics gives very simple answer on this question: there are 5 stages of development of every language: modern, old, stage of the common-language unity, pre-language and proto-language. For Slavic languages: modern languages, one so called Old-Slavic, one Common-Slavic (unified for West, East and South Slavs) and therefore one Pre-Slavic (a real language separated from the Indo-European one) and one Proto-Slavic (a dialect of Indo-European one). The Old Slavic existed in X century AD, the Common-Slavic was in fifth, the Pre-Slavic in Antiquity and the Common-Indo-European with its dialects including Proto-Slavic was in Bronze epoch. That all is very transparent.
The first doubt came to me as I began to read the inscriptions from the Iron epoch on some things from Byelorussia where instead of Slavic root PRJA- I have read there PRA-, the difference conserved in modern East Slavic languages. So I saw that some differences between two East Slavic languages were a thousand years older than we usually think about it. It means that the stage of the Common-Slavic language was really much earlier than in the fifth century AD. The second doubt rouses up from my observation that the South languages have much quicker development than the North ones. It means that the Old Slavic language cannot be of the South origin as it is, for these aims it is too young.
From these simple statements we can see acute necessity of elaboration a theoretical model of language development in space and time.
Theoretical model. Let us imagine the picture of ethnic spreading as a usual spreading of a wave in physics. Then we have to draw a sequence of circles going from one center which we can consider as origin, fig. 1. Doing simplest model imagine only three circles which we shall name as Center (C), Middle (M) and Periphery (P) areas that can remind us the modern astrophysical model of a Big Explosion Universe.
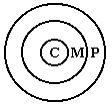
Fig. 1. Spreading of ethnics
With this Simplest Ethnic Spreading Model (SESM) we can do such assumptions:
1. The C area represents the origin of a language in space. However the primary stage of the language cannot be preserved.
2. The P area represents the development stage of the primary language in time. However the primary location of the language cannot be preserved.
3. The M area does not preserve neither primary location nor primary stage of a language. But it is convenient for comparison as location as development of a language.
The assumptions 1-3 represent the ontology of ethnic spreading process.
4. If we investigate P area, we can reveal the origin stage of a language.
5. If we investigate C area, we can reveal the origin place of a language.
6. If we investigate M area, we cannot reveal neither origin state nor origin place of a language, but we can reveal intermediate stages and places of spreading of a language.
7. If we investigate CMP areas, we can reveal the full picture of spreading and development of a language in space and time.
The assumptions 4-7 represent the epistemology of ethnic spreading process.
The modified in space model. The Modified in Space Ethnic Spreading Model (MSESM) we can see if we image the wind blowing the waves, fig. 2.

Fig. 2. The modified in space model of ethnic spreading
Here three stages of a wind are represented: slight (1), strong (2) and storm (3) wind. Under the wind we can imagine some natural and social reasons: earthquakes, fires, floods, epidemics, migrations of food animals, wars and so on. As a result we see a center replacing. It means that new center of the P and an M area already does not coincide with the true center of a language-origin. The true center is now aside in the direction of the wind.
Other changes will be the results of the place relief. The area in such case does not preserve its shape as a circle end become a formless spot, probably torn, as we can see on the fig. 3.
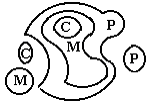
Fig 3. Another modified in space model of ethnic spreading
Here we can see a periphery replacing. The true periphery could be in the case if there exists no natural or social obstacles (mountains, hills, seas, lakes, rivers, forests, other tribes and so on).
The pecular cases. If a Slavic tribe from different reasons transverses to a foreign language (the process of "foreignisation"), the proper territory is in that aspect lost for other Slavic tribes as if here there are some natural or social obstacles (see above). It is L-area (lost area). On the contrary if a non-Slavic tribe transverses to a Slavic language of that area ("slavinisation") for a period of time this tribe will be in some respects as a Slavic one. But after the period of time the stage of language of that area will be higher than of Slavic tribes one for the velocity of language development here is mach more, as no Slavic language traditions brakes such development. Therefore on this place we can see a secondary center of language spreading. It is S-area (secondary area). It cam be a lot of such areas on the map (L1, L2, ..., Ln , S1, S2, ...Sn), Fig. 4. It is a Complicated Ethnic Spreading Model (CESM).
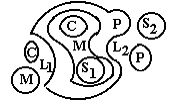
Fig. 4. The complicated case with L- and S-areas
The radioactive decay of a word. We can use to solve our problems the nuclear physics model of an stimulated atom. From the point of view of phonetics any word is probably excited that means every word is too big to pronounce it. For example, the English word YES is for Americans too big, and they short it to YE, or the name WilLyam has too much letters, and they short it to BILL. In the latter case we see two processes, first is transformation (W into B), and second is radiation (as if the ending -YAM goes away into space). As any physical process has a tendency to minimize its energy a big word with a course of time can throw down some part of it and become shorter. It means that a person has to spend little acoustical energy to pronounce it than before. We can say that through the radiation a word come from more exited state to less exited one or to final state or from one level of exiting to another; it means a word is radioactive. After any act of radiation a word becomes shorter and increases its entropy.
The verb "to be" as a main model. Now we have to choose the most representative word of a language to demonstrate on it the radioactive model of decay. No doubt that in every European language it is the verb "to be" in the III-d person of singular. Also the ground, no exited state in Slavic languages is to be JE, or the A-state (as in Slovenian). The next state or the B-state is JEST (as in Polen). The third or the C-state is JESTJ (the J after consonant is so called "soft sign" - as in Russian). The forth, hypothetical D-state is *JESJTJ (star sign means namely the hypothetical state). The decay is as follows: *JESJTJ > JESTJ > JEST > JE. Such model is common in Slavic languages with their open syllables. But for the slavinized or non-Slavic languages another model is typical: *ESJTJ > EST > ES/IS > E. So on this simplest model of a language development we can obtain a good criterion to distinguish the languages inside one language family.
It is important to stress that every state of a language is understandable only from the point of view of the language history. In the living oral communication the language of another stage and semi-stage (for example A and AB) is quite no understandable to the speaking person. It is for him a foreign language that demands an interpreter to assure the proper understanding.
Additional model. Besides the main model there exists a lot of additional ones where we can see the same laws. For example we can consider the decay model *VOLOKЪ > VOLOK > VOLK > VLK (wolf). The etymology of this word is transparent: wolf is an animal who can VOLOИITI (to drag) its victim. In non-Slavic languages on the B-state was borrowing of the word VOLK and its transformation into WOLF, WULF, (VO)LP > LUPus and so on.
The additional model or models can help us to understand which of two Slavic languages stadial older is if we cannot decide this problem with the main model: for example the main model gives us the same C-state to modern Russian and to the Old Slavic. But for the C-state words in modern Russian such as GOLOVA (head), ZDOROVJE (helth), MOLOKO (milk) and so on we see in Old Slavic the B-state words GLAVA, ZDRAVJE, MLEKO and so on. It means a paradox result that modern Russian is stadial older than Old Slavic! But it is no strange from the point of view of SESM.
The comparison of Slavic languages. Now we can solve principally the problem of the stadial age of any Slavic language. From the point of view of A-state language, for example of Slovenian the languages of that type (Serbo-Croatian) are modern, the languages of B-state (for example Polish) are old, the languages of BC-state (for example Old Slavic) and the languages of C-state (for example modern Russian) are pra-Slavic (although the modern Russian is a living language). But from the point of view of B-state languages (for example Polish) the languages of A-state type are the future ones, of B-state are the modern, of BC and C-state are old ones. But from the point of view of BC (for example Old Slavic) or C-state languages (for example modern Russian) the languages of A-state type are the remote future ones, of B-state are the future ones, of BC (for example Old Slavic for Russian) are slight future and C-state are modern ones. But for Old Slavic Russian is slight old language. Such is linguistic relativity depending of the position of an observer.
The Slavic center. Where was the center of Slavic spreading? According to SESM it is to be area in Europe in some distance from North (Slavs of Polen), South (Balkan Slavs), West (German or Baltic Slavs) and East (Russian Slavs). The most probability falls on Slovenia. To this land point two evidences yet: the number of dialects in a language (the most over all Slavic languages) and the most Slavic name (beside Slovenian only Slovaks and Novgorod Slovenians have similar but not full identical names). And from the point of view of stage model it is the Slovenian that has the A-state position.
What we can wait from the ancient language? As we could see above stadial most old among living Slavic languages is Russian. In East Slavs languages now it is very actual the process of splitting of the East Slavs languages into three separated and distinguishable from the first sight languages: Russian, Byelorussian and Ukrainian. In the XIX century the linguists regard them as only dialects of Russian and such variant of Russian had not their own writing. If such processes are very actual for the C-state languages today that means that they were such actual some thousand years ago for the nowadays A-state languages. I suppose that no later than in XX-XV centuries BC a similar processes went in the Central Slavic languages, for example in Venetic, Rhetic and Etruscan.
Some evidences. What was the state of the Central Slavic languages? According to the book of Anthony Ambrozic "Adieu to Brittany" (Toronto, 1999) the form JE as the III-d person singular of the verb "be" on the Venetic is written there on the pages 9, 29, 32, 37, 41, 55, 76, 76, 76, 79, 80, 81, 82, 84, that is 14 times. Therefore the inscriptions of the first centuries AD show us that Venetic in that time was on the A-State and existed as a separated language no less than 2 thousand years. But he has collected the samples in the region of Lusitian culture, on the North-West of Europe.
Another evidence I have obtained from Etruscan. In the book of I.V. Davidenko "Fals lighthouses of history" (Moscow 2002, p. 39, in Russian) we can see an Etruscan rosette of the VII century BC, fig. 5.
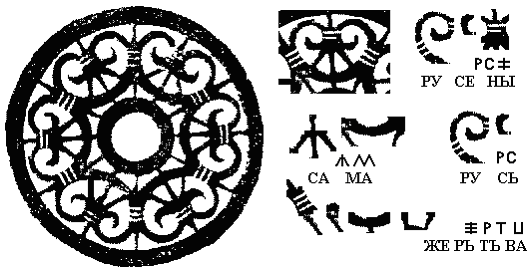
Fig 5. My reading of the Etruscan rosette
On the curls I read in Runica their own name that was RUSENI (RUSENS), then two words SAMA RUS that have meaning THE VERY RUSSIA (EUROPE) and the word ZHERTVA (VICTIM). Earlier from the Greek sources we knew that own name of Etruscans was RASENS. Here I suppose the name is given more exactly. And the sentence of the words THE VERY RUSSIA talks us that Etruscans consider themselves as the inhabitants of the very Center of Europe. The word VICTIM says us that the rosette was made as a salver on the victim fireplace. But namely for Etruscans we can suppose a strong influence on it of some non-Slavic languages on the last epoch of its existence that gradually made it non-Slavic.
Conclusions. The languages of Central Slavic group (Venetic, Rhetic and Etruscan) in spite of their great age have no reasons to be considered as pre-Slavic ones. On the contrary in comparison not only with modern Russian, but with C-state Latin (the main verb is EST) and C-state Greek (EIMAI=IME) they precede the latter on the stage of development being on the A-state and relating to them as modern to pre-European ones. Therefore we can expect of them a lot of dialects with similar but different writing forms of words. It will be connected with some difficulties during the reading and deciphering of inscriptions. If we can reveal them (the sentence of inscriptions) we can see that not Latin and Greek tribes were the origins of European culture in the past, but Slavic tribes - all the history including Antiquity.
Написать отзыв
Вы должны быть зарегистрированны ввойти чтобы иметь возможность комментировать.